13. Data Assimilation
13.1. Introduction to concepts
Data Assimilation (DA) is a set of statistical techniques to obtain estimates of some state vector \(x\) by merging information from observations \(y\) and any prior (background) information on the state, \(x_b\). The translation between the state vector and the observations is achieved through an observation operator \(H(x)\) which proposes an estimate of the observations \(\hat{y} = H(x)\).
In this lecture, you will be introduced to some of the underlying statistical concepts, some of the methods you can use for DA, and some applications.
13.1.1. Some basic Gaussian statistics
Importantly, the uncertainties in all of these elements must be taken into account. If we assume Gaussian (Normal) distribution of uncertainty, then the prior distribution (what we believed the state to be before we included information from any observations) is:
\(^T\) here denotes the transpose operation.
It is important that you understand the notation and concepts here, so we will pause to consider what equation (1) means for a moment.
The term \(P_b(x)\) expresses the probability of the state \(x\) being any particular value, where \(x\) in the general case is a vector. This is the probability distribution function (PDF). You would normally use this to describe what the probability is of \(x\) lying between some limits (i.e. you integrate the PDF over some limits).
As a probability, the PDF is normalised so that its integral (over the entire bounds of possibility) is unity. The term \([1/((2 \pi)^{n/2} \sqrt{\det(B)})]\) expresses the scaling required to make that so.
The matrix \(B\) expresses the variances and covariances between elements of \(x\). So, for example, if \(x\) had only two elements, \(x_0\) and \(x_1\), it would look something like:
or alternatively:
where \(b_{i,j}\) is the covariance between state element \(i\) and \(j\) (remember that the covariance between element \(i\) and itself, is of course the variance). Note that the matrix is symmetric about the leading diagonal (\(b_{i,j} \equiv b_{j,i}\)).
We assume that students are at least familiar with the univariate concepts of the mean and standard deviation of a Gaussian distribution. For this multivariate case then, we have a standard deviation in the parameter (state vector element) \(x_0\), being \(\sigma_{0}\) and one in the parameter \(x_1\), being \(\sigma_{1}\). These of course define the spread of the distributions of each of these terms. These control the leading diagonal elements of the matrix \(B\) (they are squared in the matrix, so are stated as variance terms).
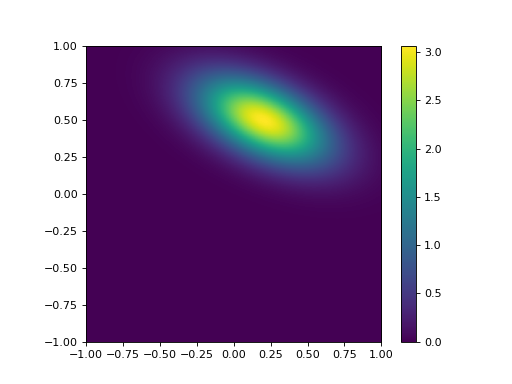
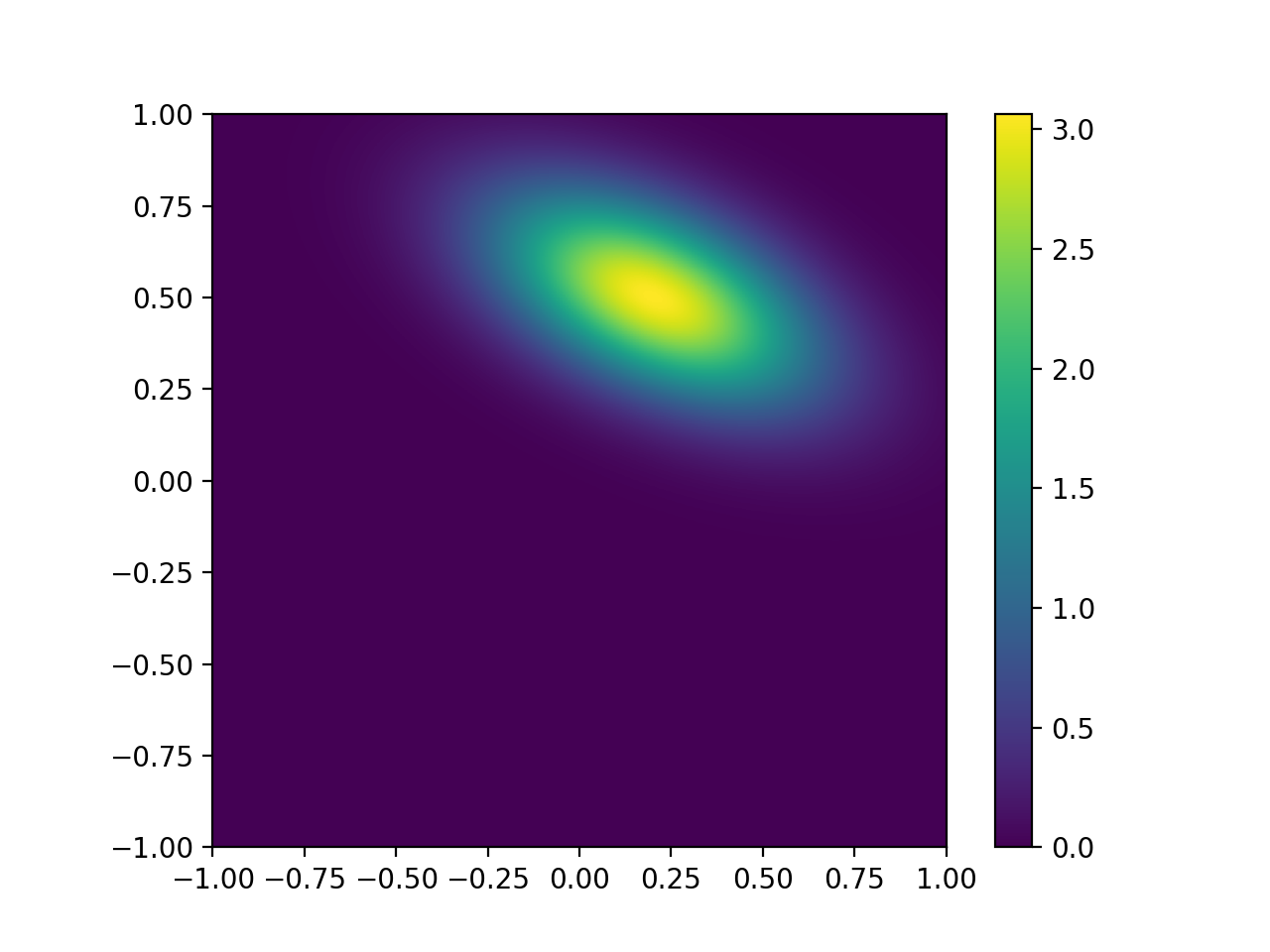
The term \(\rho_{0,1}\) is the correlation coefficient, which ranges from \(-1.0\) to \(1.0\) and expresses the degree of linear correlation between \(x_0\) and \(x_1\). This is just a normalised expression of the covariance. As an example, we consider a distribution with \(x = [ 0.2, 0.5 ]^T\) and \(B = [[0.3^2 , -0.5 \times 0.3 \times 0.2][-0.5 \times 0.2 \times 0.3,0.2^2 ]]\):
from plotGauss import *
mean_0 = 0.2
mean_1 = 0.5
sd_0 = 0.3
sd_1 = 0.2
rho = -0.5
plotGauss(mean_0,mean_1,sd_0,sd_1,rho)
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
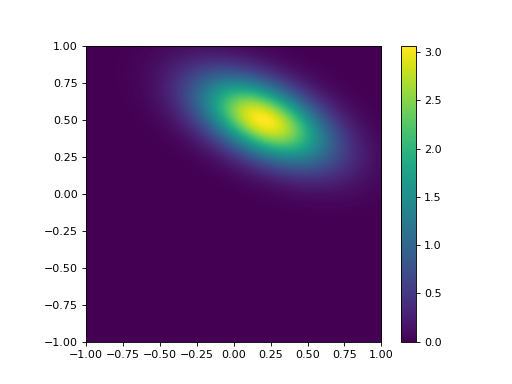
This might seem rather trivial to some students, but it is best to make sure that you have these concepts clear in your head when considering the statistics here.
The determinant of \(B\), used in equation (1), is a measure of the total variance expressed by the matrix. In the trivial example for which \(\sigma_{0} = \sigma_{1}\) and \(\rho_{0,1} = 0\), \(\det(B) = \sigma_{0}^2\), so \(\sqrt{\det(B)} = \sigma_{0}\) is a measure of the total ‘equivalent’ standard deviation (the width of the distribution, if you like, in the same units as \(x_0\) and \(x_1\)). You should be able to see more clearly now how the scaling factor arises.
In the univariate Gaussian case, you may be used to considering a term such as a Z-score, that is the normalised distance of some location \(x\) from the mean, so \(Z^2 = [(x - x_b)/\sigma_x]^2\) should be a familiar concept. The multivariate equivalent is just: \(Z^2 = (x - x_b)^T B^{-1} (x - x_b)\), where \(B^{-1}\) is the inverse of the matrix \(B\), the equivalent of \(1/\sigma_x^2\) in the univariate case.
Whilst you will generally use computer codes to calculate a matrix inverse, it is instructive to recall that, for the symmetric \(2 \times 2\) matrix \(B\) above, the inverse, \(B^{-1}\) is given through:
We can verify this:
where \(I\) is the Identity matrix. In Python:
import numpy as np
sd_0 = 0.3
sd_1 = 0.2
rho = -0.5
# Form B
B = np.matrix([[sd_0**2,rho*sd_0*sd_1],[rho*sd_0*sd_1,sd_1**2]])
# inverse
BI = B.I
# check:
print 'B x B-1 = I'
print B,'x'
print BI,'='
print BI * B
B x B-1 = I
[[ 0.09 -0.03]
[-0.03 0.04]] x
[[ 14.81481481 11.11111111]
[ 11.11111111 33.33333333]] =
[[ 1.00000000e+00 -5.55111512e-17]
[ 0.00000000e+00 1.00000000e+00]]
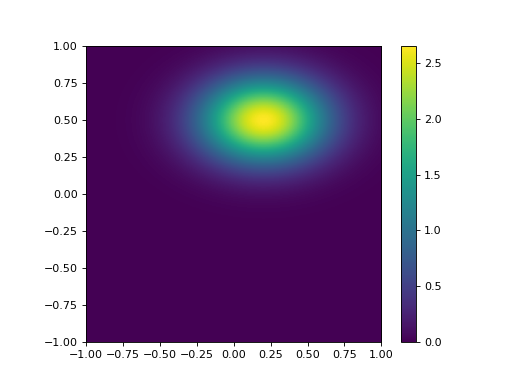
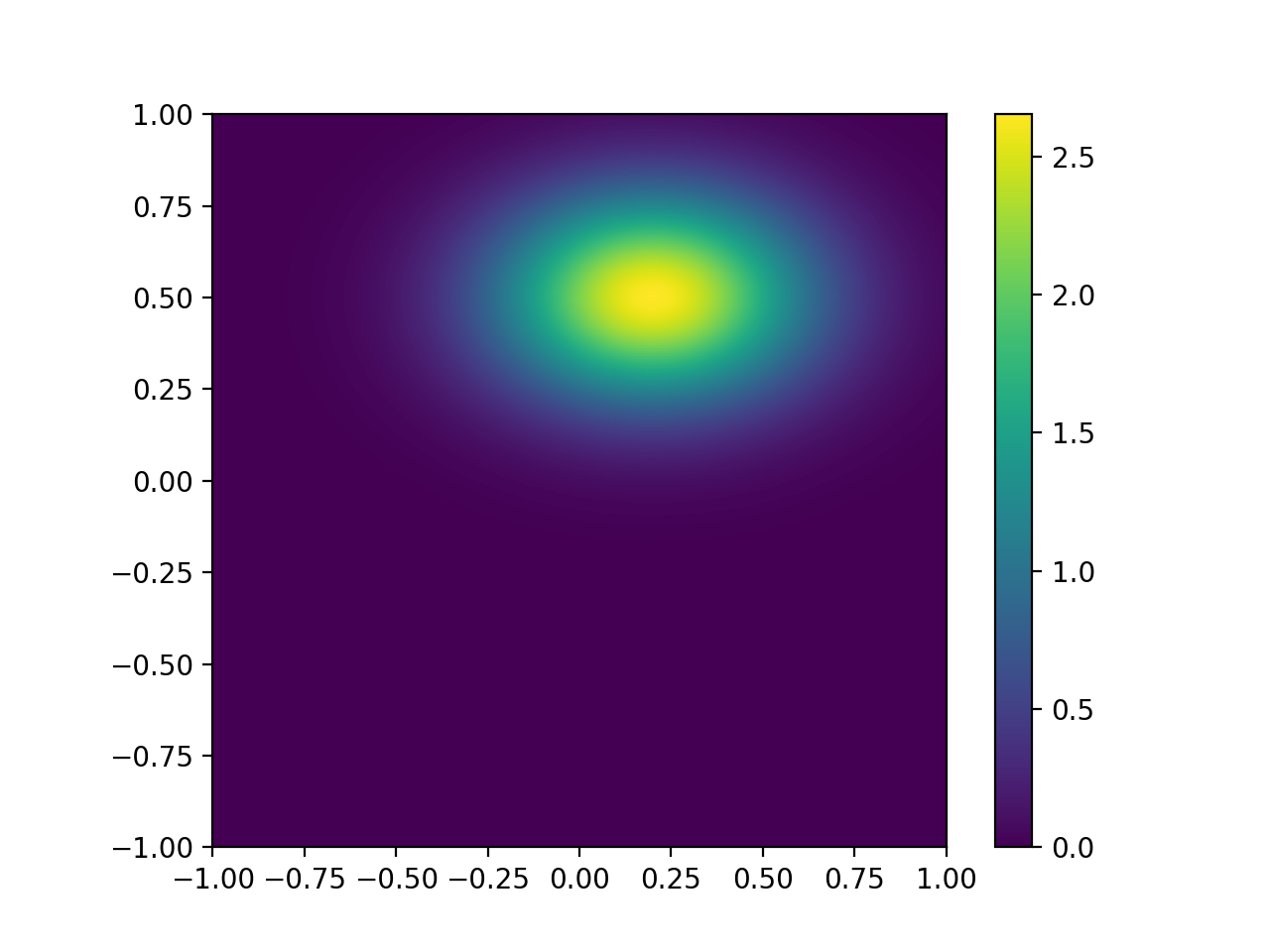
We will see that in many DA exercises (and quite often when statistics are used) the off diagonal elements of a matrix (the covariance terms) are ignored (i.e. set to zero). Sometimes this is simply because nothing is really known of the covariance structure. In this case of course, we obtain a distribution of the form:
from plotGauss import *
mean_0 = 0.2
mean_1 = 0.5
sd_0 = 0.3
sd_1 = 0.2
rho = 0.0
plotGauss(mean_0,mean_1,sd_0,sd_1,rho)
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
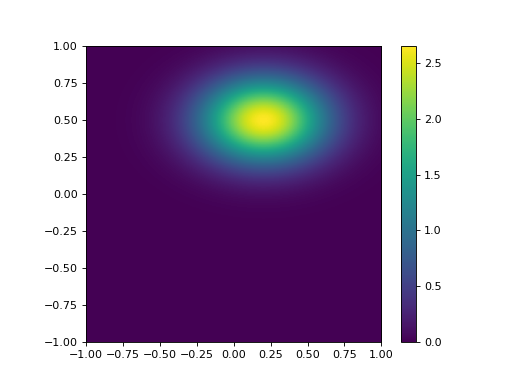
which is aligned to the axes. We can see immediately that this is quite different to that with a correlation coefficient of -0.5, so we must recognise that we cannot lightly ignore such correlation information, however pragmatic or convenient it might seem to be.
If, in the above examples, we consider the probability of the coordinate \([0,0]\) in these distributions, we can note that it is:
import numpy as np
mean_0 = 0.2
mean_1 = 0.5
sd_0 = 0.3
sd_1 = 0.2
# case 1: with correlation
rho = -0.5
test = [0.,0.]
dx0 = test[0] - mean_0
dx1 = test[1] - mean_1
B00 = sd_0**2
B11 = sd_1**2
B01 = sd_0 * sd_1 * rho
Z2 = (dx0*B00+dx1*B01)*dx0 + (dx0*B01+dx1*B11)*dx1
detB = B00*B11 - B01**2
scale = (2.*np.pi) * np.sqrt(detB)
p0 = (1./scale) * np.exp(-0.5 * Z2)
print 'p0: rho = -0.5: p(0,0) =',p0
# case 1: without correlation
rho = -0.0
test = [0.,0.]
dx0 = test[0] - mean_0
dx1 = test[1] - mean_1
B00 = sd_0**2
B11 = sd_1**2
B01 = sd_0 * sd_1 * rho
Z2 = (dx0*B00+dx1*B01)*dx0 + (dx0*B01+dx1*B11)*dx1
detB = B00*B11 - B01**2
scale = (2.*np.pi) * np.sqrt(detB)
p1 = (1./scale) * np.exp(-0.5 * Z2)
print 'p1: rho = 0.0: p(0,0) =',p1
print 'p1/p0 =',p1/p0
p0: rho = -0.5: p(0,0) = 3.05132122876
p1: rho = 0.0: p(0,0) = 2.63460601358
p1/p0 = 0.863431220793
So, If we assume no correlation we would underestimate the probability of \(x\) being \([0,0]\) by a factor of 0.863 in this case.
13.1.2. Combining probabilities
Now we have got some appreciation of multivariate Gaussian statistics we can think about how this all works when we combine distributions. This is at the heart of any DA approach. The most fundamental idea in this can be expressed by Bayes theorum:
where we understand \(P(a | b)\) as a conditional probability, the probability of \(a\) given \(b\).
Suppose we have some observations \(y\), and we have a model (observation operator) that provides an estimate of \(y\), \(\hat{y}\) for some values of \(x\):
so
where \(\epsilon\) are the errors arising from the modelling of \(y\) and any errors in \(y\) itself (noise in the observations).
The PDF of the observations is the PDF of the observations given \(x\):
The observation PDF is now:
where \(R\) is the variance-covariance matrix expressing the uncertainty in the model and the observations (i.e. the summary statistics of \(\epsilon\)).
Using Bayes theorem:
Here, \(P(y)\) is simply a normalising term that we could express as \(P(y) = \int p(y | x) p(x) dx\), so we can write more simply:
The importance of this then is that we can combine probabilities by multiplication of the PDFs. If we have a previous estimate of \(x\), \(x_b\), and the observations \(y\), then we can get a new (improved) estimate of \(x\), \(x'\) through:
or more clearly:
provided \(H(x)\) is linear (otherwise we don’t get a Gaussian distribution when we apply \(H(x)\)), we can write: \(H(x) = Hx\) where \(H\) is the linear observation operator.
The optimal estimate of \(x'\) can be found by finding the value of \(x\) which gives the maximum of the likelihood (probability) function (the maximum of equation (6)). Because of the negative exponential, this is the same as finding the value of \(x\) that gives the minimum of equation (5). This is found by solving for the value of \(x\) for which the partial differentials of \(J(x)\) with respect to \(x\) are zero.
The differential of \(J(x)\), \(J'(x)\) is known as the Jacobian.
We can recognise that \(J(x)\) as a form of cost function which is itself the addition of other cost functions. Each of these cost functions provide a constraint on our (optimal) estimate of \(x\): \(J_b(x)\) constrains the solution by our former belief in its state (the background); \(J_o(x)\) provides a constraint based on observations.
We can estimate the posterior uncertainty (matrix, here) from the curvature of the cost function. This is found by the inverse of the second differential of \(J(x)\), \(J''(x)\), which is known as the Hessian.
For a diversion, we can calculate the Jacobian and Hessian terms from equations (3) and (4). For the Jacobian:
or in the linear case:
And for the Hessian:
or in the linear case:
It is worth considering the Hessian in the linear case in a little more detail. The prior uncertainty (i.e. what we knew before we added any observations) was simply \(B\).
After we add information (observations) the posterior uncertainty, \(C_{post}\) is:
In the simplest case, we might suppose that we have a direct observation of the state vector \(x\), so \(H(x) = Ix = x\), where \(I\) is the identity operator, or more simply, \(H=I\). Then:
In the univariate case, consider when we have two observations of \(x\), say \(x_a\) and \(x_b\), with uncertainties (standard deviations) \(\sigma_a\) and \(\sigma_b\) respectively. The uncertainty after combining these two observations, \(\sigma_{post}\) is expressed by:
and the resultant uncertainty will always be less that either of the two uncertainties. In the most trivial case where \(\sigma_b = \sigma_a\),
Provided the evidence (data) that we combine is independent, we reduce the uncertainty by combining samples.
The ‘optimal’ estimate of \(x\) in the univariate example above is found by setting \(J'(x)\) to zero:
which is rearranged as:
or
which is just a variance-weighted mean of the two observations: in the trivial case where the uncertainty in the observations is the same for both samples, we have simply the mean as the optimal estimate, which is what you would expect.
Clearly, this is a very simple example, but thinking through and understanding such cases can help you develop a deeper appreciation of the more complex (general) cases and also help you to develop some ‘mathematical intuition’ into such problems.
To illustrate this for a two-dimensional example:
import numpy as np
import scipy.optimize
# prior
xb = np.array([0.1,0.5])
B = np.matrix([[0.2**2,0.5*0.2*0.3],[0.5*0.2*0.3,0.3**2]])
# a direct observation: sd = 0.1
xr = np.array([0.15,0.4])
R = np.matrix([[0.1**2,0.0],[0.0,0.1**2]])
BI = B.I
RI = R.I
# starting guess
x = np.array([0.,0.])
def cost(x,xb,BI,xr,RI):
'''
Return J and J' at x
'''
Jb = np.dot(np.array(0.5*(xb-x) * BI),(xb-x))[0]
Jr = np.dot(np.array(0.5*(xr-x) * RI),(xr-x))[0]
JbPrime = -(xb-x)*BI
JrPrime = -(xr-x)*RI
return Jr+Jb,np.array(JrPrime+JbPrime)[0]
def uncertainty(x,xb,BI,xr,RI):
# inverse of Hessian
return (BI + RI).I
retval = scipy.optimize.fmin_l_bfgs_b(cost,x,args=(xb,BI,xr,RI))
# x new
x = retval[0]
# uncertainty
Cpost = uncertainty(x,xb,BI,xr,RI)
# print prior
psigma0 = np.sqrt(B[0,0])
psigma1 = np.sqrt(B[1,1])
prho12 = B[0,1]/(psigma0*psigma1)
print 'prior: x0,x1 :',xb[0],xb[1]
print 'prior: sd0,sd1,rho:',psigma0,psigma1,prho12
# print observation
rsigma0 = np.sqrt(R[0,0])
rsigma1 = np.sqrt(R[1,1])
rrho12 = R[0,1]/(rsigma0*rsigma1)
print 'observation: x0,x1 :',xr[0],xr[1]
print 'observation: sd0,sd1,rho:',rsigma0,rsigma1,rrho12
sigma0 = np.sqrt(Cpost[0,0])
sigma1 = np.sqrt(Cpost[1,1])
rho12 = Cpost[0,1]/(sigma0*sigma1)
print 'posterior: x0,x1 :',x[0],x[1]
print 'posterior: sd0,sd1,rho:',sigma0,sigma1,rho12
prior: x0,x1 : 0.1 0.5
prior: sd0,sd1,rho: 0.2 0.3 0.5
observation: x0,x1 : 0.15 0.4
observation: sd0,sd1,rho: 0.1 0.1 0.0
posterior: x0,x1 : 0.130487804878 0.415853658537
posterior: sd0,sd1,rho: 0.0869538705852 0.0937042571332 0.0898026510134
Here, we have used the theory laid out above, with an Identity observation operator. Rather than trying anything fancy with finding the minimum of the cost function, we simply call an optimisation routine (scipy.optimize.fmin_l_bfgs_b in this case) to which we provide a cost function that returns \(J\) and \(J'\) for a given \(x\). We then calculate the uncertainty from the inverse of the Hessian as described above. Actually, we will see that this is sometime quite a practical approach.
We can illustrate the results graphically:
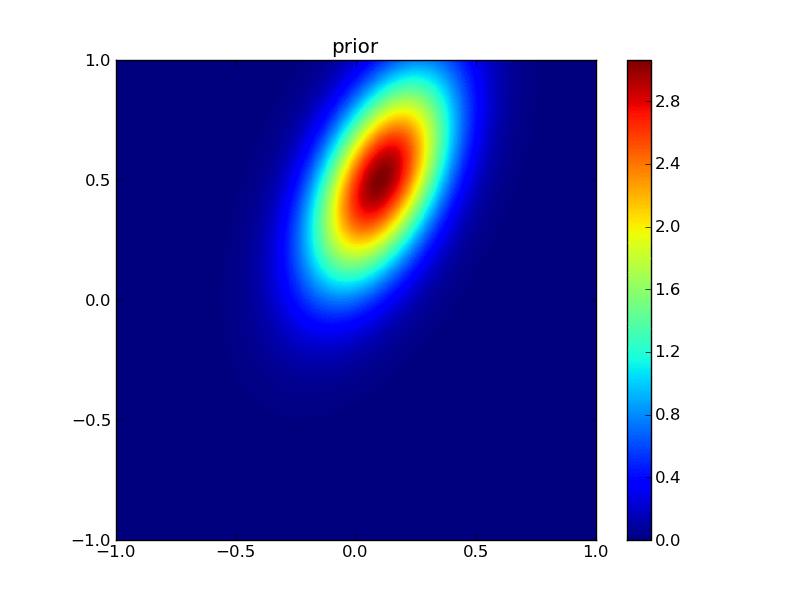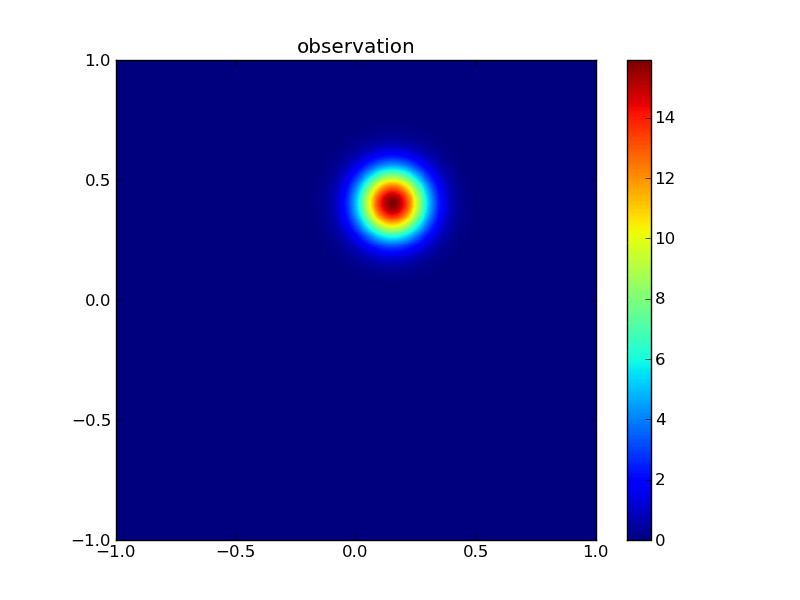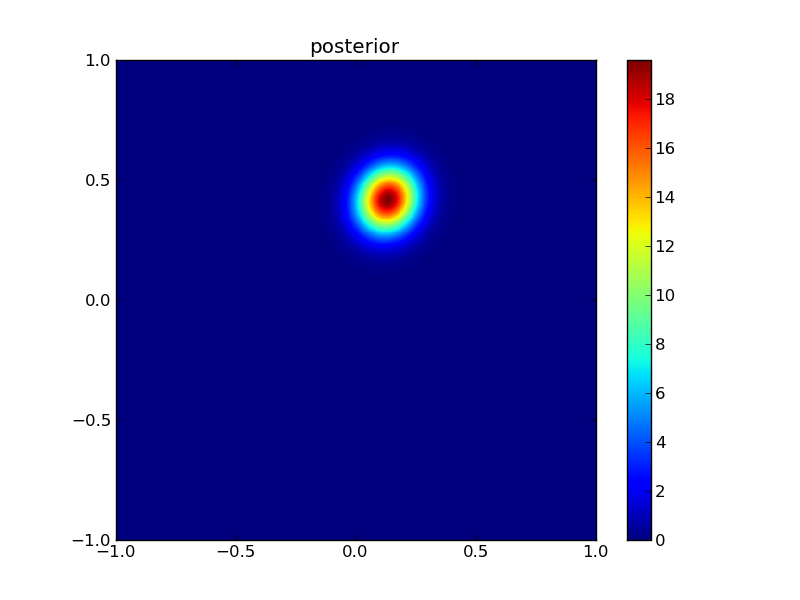
First, plot the priors:
from plotGauss import *
plotGauss(xb[0],xb[1],psigma0,psigma1,prho12,\
title='prior',file='figures/Tprior.png')
integral of Gaussian: 0.952539606871
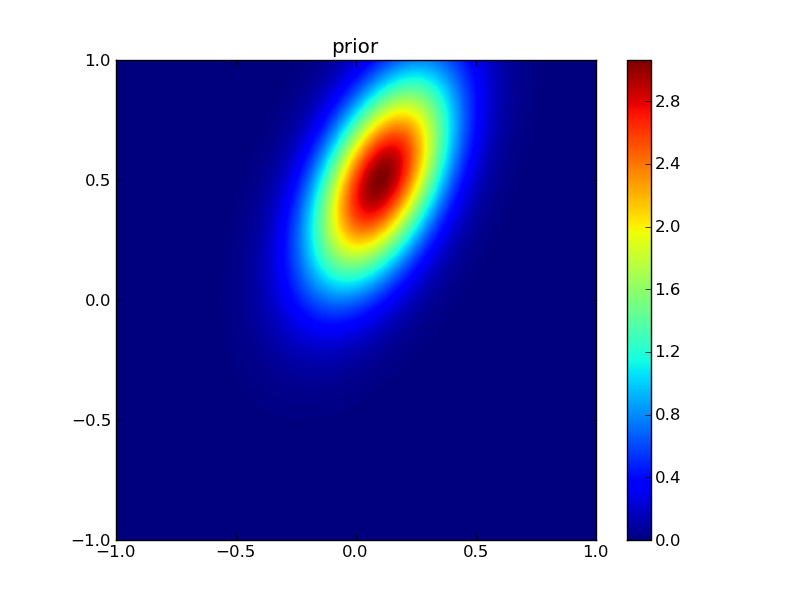
Then the observations:
plotGauss(xr[0],xr[1],rsigma0,rsigma1,rrho12,\
title='observation',file='figures/Tobs.png')
integral of Gaussian: 0.999999999073
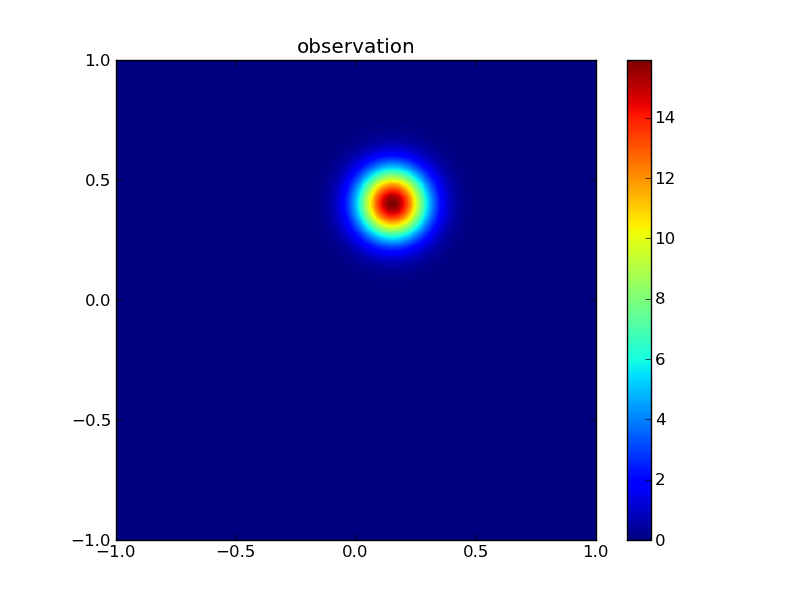
Then the posterior:
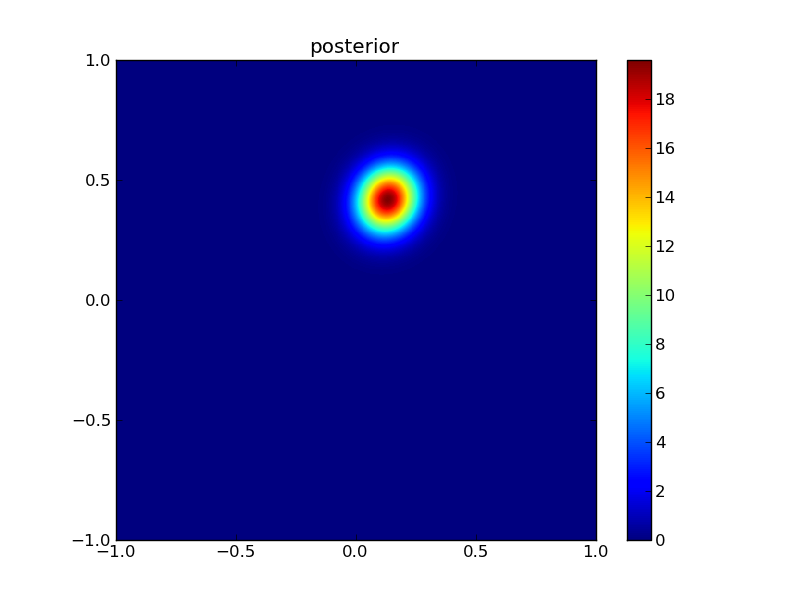
plotGauss(x[0],x[1],sigma0,sigma1,rho12,\
title='posterior',file='figures/Tpost.png')
integral of Gaussian: 0.999999999788
Aside: to make a movie from this, which is quite interesting, its probably easiest to use the unix tool convert which is part of the ImageMagick package. To interface to this from python:
import os
files = 'figures/Tprior.png figures/Tobs.png figures/Tpost.png'
os.system('convert -delay 50 -loop 0 %s figures/Tanim.gif'%files)
13.1.3. Measuring improvement
A measure of reduction in uncertainty is found from the ratio of the posterior uncertainty to the prior uncertainty in some form. One common measure that involves such ideas is the relative entropy.
The concept of relative entropy comes from information theory (Cover & Cover, 1991). Entropy (in information theory) is a measure of the amount of information needed (on average) to describe a random variable (i.e. one with uncertainty). The relative entropy (or Kullback Leibler distance) then is a measure of the ‘distance’ between two distributions, in this case, the prior and the posterior distributions.
One part of the relative entropy can be expressed as dispersion (Kleeman, 2002) of the posterior \(C_{post}\) relative to the prior \(C_{prior}\):
where \(tr(C)\) denotes the *trace* operator (the sum of the diagonal elements) and \(n\) is the rank of the matrix (the number of elements in \(x\)).
Another metric is a form of ‘distance’ moved by the mean state relative to the prior uncertainty in going from the prior mean to the posterior (the ‘signal’):
These can be combined into a measure known as the relative entropy of the two distributions:
where the \(\ln{2}\) normalisation converts the measure to units of bits.
Taking our univariate example with equal variances above, we obtain: \(D = (1/2)(\ln{2} + (1/2) - 1) = 0.097\). Here, \(\det{C_{prior}}/\det{C_{post}} = 2\) (the reduction in uncertainty as expressed by the matrix determinants) whereas \(tr(C_{post} C_{prior}^{-1}) = 1/2\) gives a summary of relative variance terms. If there was no information added, then the posterior would be the same as the prior and we would get a value of \(D = \ln{(1)} + n - n = 0\). In ‘bits’, the relative entropy then (ignoring the signal part) is \(0.097/\ln{2} = 0.14\) in this case. It is not very straightforward to interpret such units or such information measures, but they do at least proivide even the novice DA person with a relative measure of information content after data have been added ralative to what was known before.
Looking at the solution that we provided illustrative examples for (two samples, but different variances) we can calculate:
# just remind ourselves of the values above
Cprior = np.matrix(B)
Cpost = np.matrix(Cpost)
xpre = xb
xpost = x
D = 0.5*(np.log(np.linalg.det(Cprior)/np.linalg.det(Cpost)) + \
(Cpost * Cprior.I).trace()[0,0] - Cpost.shape[0])
print 'Dispersion =',D
S = 0.5*np.dot((xpost-xpre).T * Cprior.I,xpost-xpre)[0,0]
print 'Signal =',S
print 'relative entropy =',(D+S)/np.log(2.), 'bits'
Dispersion = 1.03971286262
Signal = 0.0964455681142
relative entropy = 1.63913013369 bits
13.2. Finding solutions
We have laid out the theoretical framework for data assimilation above (assuming Gaussian statistics at the moment), and illustrated it with some simple linear examples.
Data assimilation is particularly powerful because it can be made to work with complex models and complex (large) datasets, provided appropriate methods are chosen.
In this section, we will consider some typical methods of solution.
13.2.1. Variational data assimilation: strong constraint
In many ways, the most simple way of setting up a DA system is to use variational methods directly. Variational methods (the calculus of variations) essentially tells us how to apply constraints to our estimation. In DA language, you will come across methods such as 4DVar that is an example of such a system.
The heart of this is simply the statement of a set of cost functions as we developed above:
where \(J_b(x)\) is the background or prior term as before, and \(J_{oi}(x)\) are a set of observational cost functions, associated with some set of observations.
Most typically, a dynamic model is used as a strong constraint to the problem. What this means is that, for instance in Numerical Weather Prediction (NWP), the state vector \(x\) represents a set of parameters of an NWP model. This would normally include some set of initial conditions (the current state of the weather system) and some parameters controlling the NWP model. The state vector \(x\) may be very large in such a case, as it will include a representation of the state of the atmosphere (and land/ocean surface) in some gridded form. The background (prior) might contain a climatology (average conditions that we wish to improve on) or perhaps the results of a previous analysis.
The strong constraint means that the state estimate must belong to something that can be predicted by the model. In effect, we assume that the model is correct and only the initial conditions and parameters controlling its behaviour are in error.
Using a strong constraint, we can run the NWP model forward in time (over space) to predict what the conditions will be for any particular representation of \(x\). When we have an observation available, we transform from the state space (\(x\)) to the observational space (\(y\)) with an observation operator \(H(x)\) and a representation of model and observational uncertainties \(R\).
All we then need to do, is to solve for which values of \(x\) give the minimum of the cost function over the time and space windows that we consider.
To make the problem tractable, the model \(x_i = M_{0 \rightarrow i}(x)\) is often linearised. This means that we replace \(M(x)\) by a (first order) tangent linear approximation (the derivative) so that:
where we use \(M'\) here to represent the tangent linear approximation of \(M\). Note that this is a matrix.
So long as we use this linear approximation to \(M\), we can calculate the state \(x\) at any time step by applying multiple operators:
Clearly this sort of approximation gets poorer the longer the time period over which it is applied because errors from the linearisation will stack up (even if the model and starting state were perfect).
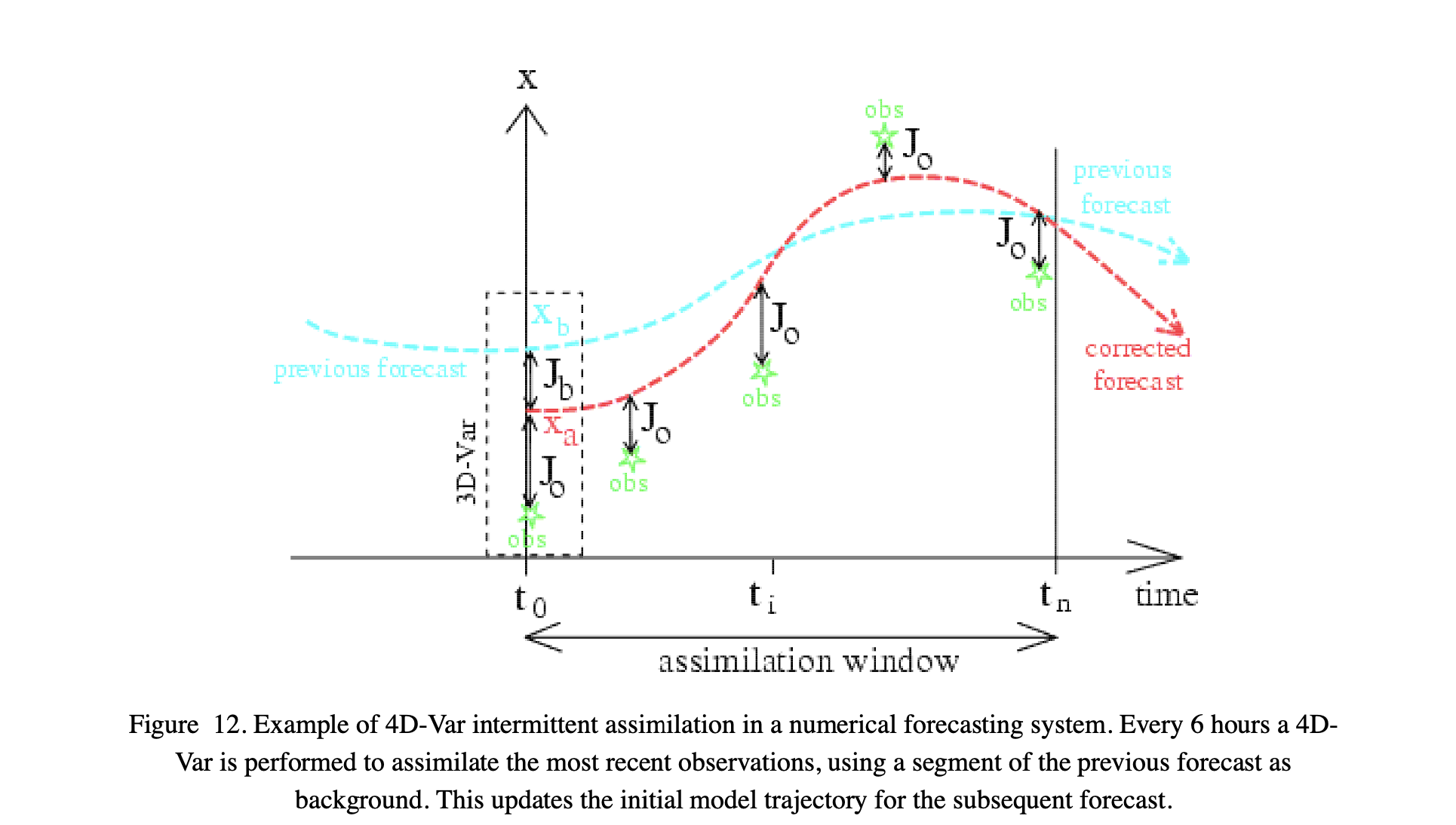
The figure above, from Bouttier and Courtier (1999) <pdf/02EC-BouttierCourter-DAconcepts.pdf> illustrates how such a strong constraint 4DVar works.
We define some assimilation window in time, which we can sample over \(n\) steps from \(t_0\). The full 4D scheme involves one of the ‘temporal’ \(x\) vectors over a 3D space.
In this example, the state \(x\) represented the paramater trajectory over time. Our background (prior) might come from a previous forecast (or in some cases average conditions) which gives us \(x_b\) and \(B\).
We have some set of (5 here) observations that we wish to use to correct the forecast. We derive a cost function that is the sum of \(J_b\) and the observational cost terms, and solve for the trajectory \(x\) that minimises the combined cost function.
This is exactly the same, in principle, to the simple ‘two sample’ solution we solved for above, and in fact the algorithm we used to find the cost function minimum (L_BFGS_B) is quite appropriate for this task, even for large state vectors.
13.2.2. Variational data assimilation: weak constraint
The strong constraint is a useful and appropriate approach so long as the model is to be trusted, at least for short-term forecasts. This is why is has been of great value in the NWP community.
Sometimes though, we make a model that we interpret only to be a guide, and not something we want to strictly enforce.
An example of this is found in the concept of smoothing (Twomey, 2002; Hansen et al., 2006).
There are many geographical and physical phenomena that are correlated in space and/or time: any two samples close by are likely to be more similar than samples far apart.
One way of expressing this as a model is through the expectation that the change in the property is zero, with some uncertainty. This is a first difference model, and when applied as a weak constraint, provides a way of optimally smoothing and interpolating between observations.
Another way of phrasing this ‘first difference’ model is to say that it is a zero-order process model (i.e. we expect tomorrow to be the same as today, with some uncertainty).
If we phrase the model as:
with uncertainty \(C\), then we can phrase a constraint through a cost function as above:
which is linear and has the derivatives:
The matrix \(D\) then, expresses the differential, so if \(x\) were simply time samples, this would look something like:
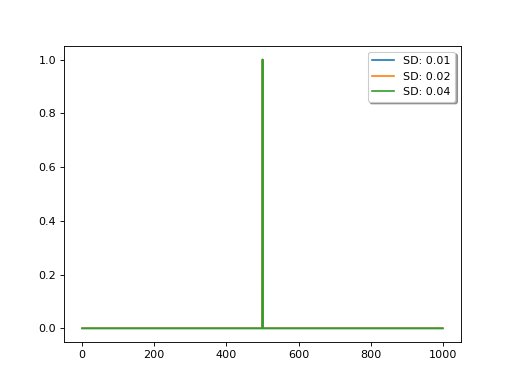
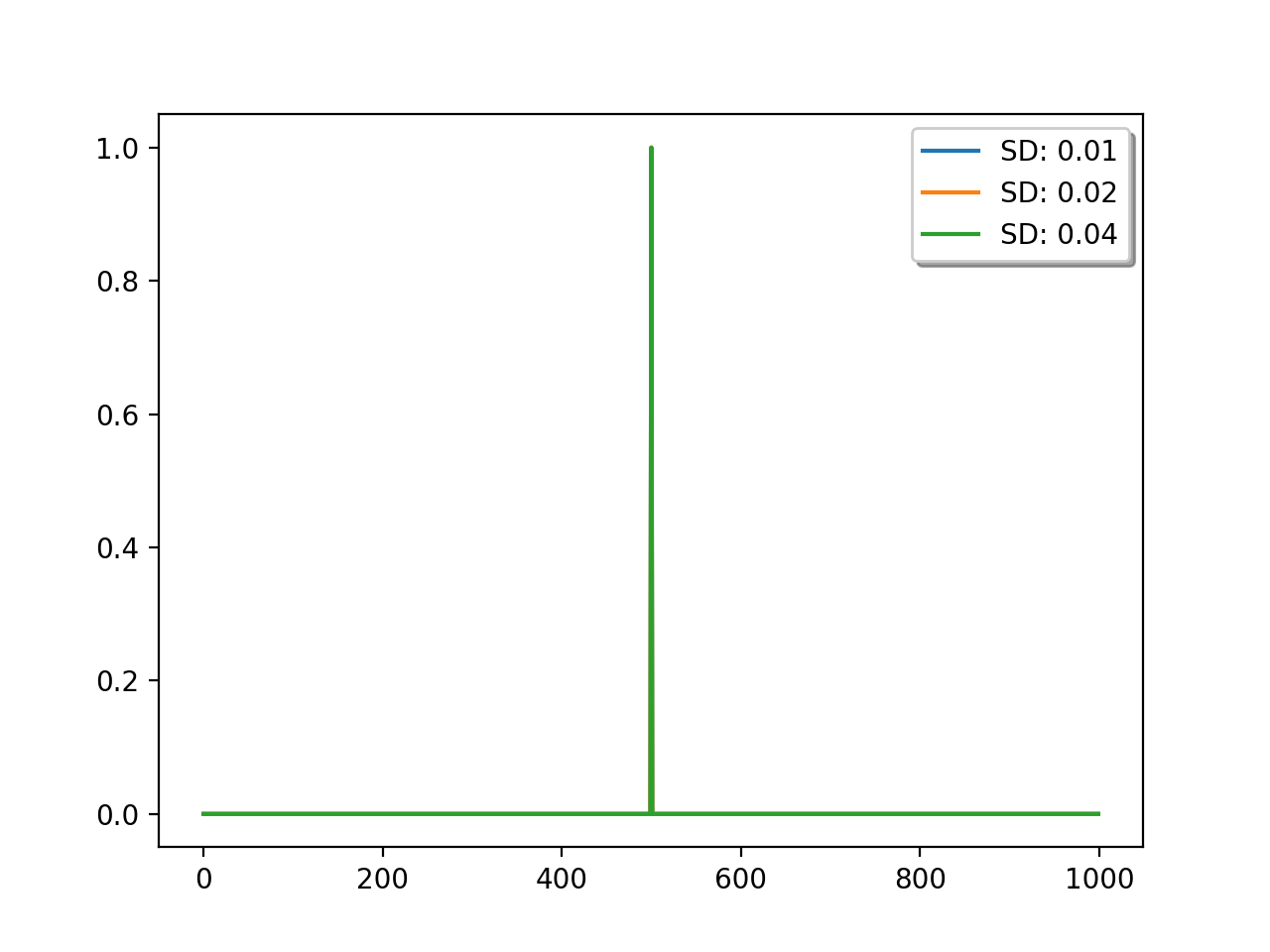
Interestingly, there is an equivalent convolution filter for this, which is a Laplace function, the width of which is controlled by the uncertainty \(C\):
import numpy as np
import matplotlib.pyplot as plt
N = 1000
I = np.matrix(np.identity(N))
# generate the D matrix
D = (I - np.roll(I,1))
# squared for the constraint
D2 = D.T * D
for sd in [1e-2,2e-2,4e-2]:
# inverse
F = (D2 + sd*sd*I).I
# plot the central line
y = np.array(F)[int(N/2)]
plt.plot(y/y.max(),label=f'SD: {sd:.2f}')
plt.legend(loc='best',fancybox=True, shadow=True )
plt.show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
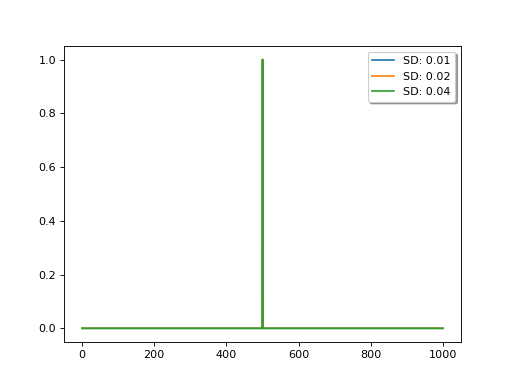
The relative uncertainty between the observations and the model (the first difference operator), expressed as sd in the code above, controls the degree of smoothing: the lower the uncertainty in the model, the more narrow the (effective) filter and the less smoothing is applied.
Applying this difference would be a poor model as a stong constraint, but can be very effective as a weak constraint.
Smoothing of this sort is also known as regularisation and has very wide application in science.
We can of course apply higher order derivative constraints and these are sometime appropriate (see Twomey, 2002). A second-order difference constraint is equivalent to (weakly) constraining the slope of the state trajectory to be constant (a first-order process model).
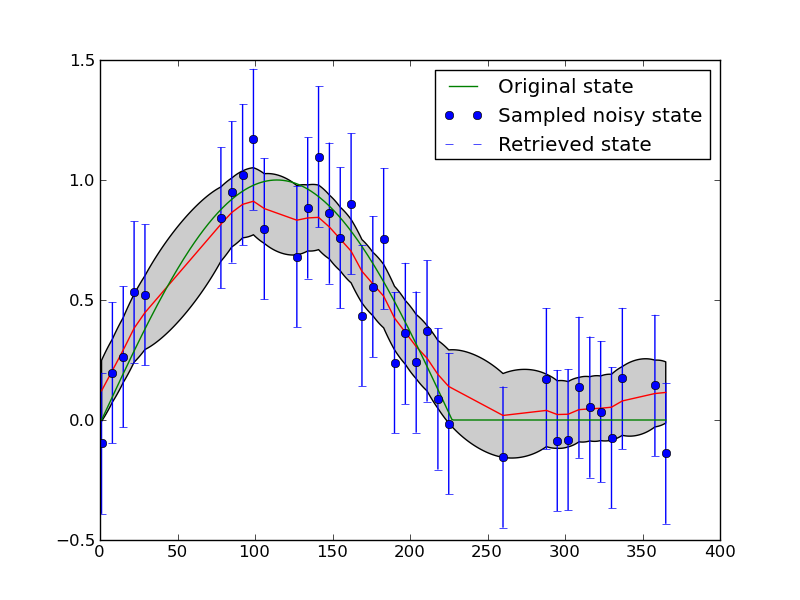
The figure above shows an application of this to filter a noisy time series. Synthetic observations (of NDVI) are generated and noise added to produce the blue dots (with given error bars). The result of applying a first difference constraint to the solution fives the red line as the mean estimate, with the grey shading as the posterior uncertainty. The green line is the original signal (from which the samples were taken). Regularisation (a first order difference model as a weak constraint) is able to reconstruct the original signal better than the original samples.
Whilst regularisation then is quite a good simple example of a weak constraint, it can of course be much more widely applied. The main advantage is that the state does not have to be something that the model predicts, which means that e.g. if some set of observations showed some phenomenon not dealt with by a model, in a weak constraint, the state would be affected by the observations. In a strong constraint, this would likely be picked up as some bias, but in a weak constraint system we can (at least partially) overcome weaknesses in model structure.
13.2.3. Sequential methods
Although variations schemes have many attractions, they only really work efficiently if some code of the tangent linear model (or more efficiently, the adjoint) exist, or all components of the constraints are linear. This is required to make the minimisation of the cost function as efficient (and fast) as possible.
Additionally, we are normally limited to making the assumption that the statistics are Gaussian.
For many appliocations, particularly real-time applications, sequential methods should be considered.
Perhaps one of the best known of these is the Kalman Filter (KF), which arose from the need to correct trajectory estimates for spacecraft. The core idea is the same as the DA methods above: we have some model of state (e.g. if we know the velocity, we know have some expectation of where an object is going), but we wish to update this with observations to improve our estimate.

[Source: Wikipedia]
In this approach, we start from some prior knowledge of the state \(x_{k-1|k-1}\) and its uncertainty \(P_{k-1|k-1}\).
Based on our (process) model, we predict what the state will be at the next time step and update the uncertainty, giving \(x_{k|k-1}\) and \(P_{k|k-1}\).
We then perform an update step, where we compare the prediction with an observation \(y_k\) (if available) and update the estimate giving \(x_{k|k}\) and \(P_{k|k}\).
We then repeat this process for further timesteps.
We can write the prediction step as:
where \(M_k\) is the model that transitions \(x_{k-1|k-1}\) to \(x_{k|k-1}\) (as a linear operator) and \(Q_k\) is the uncertainty in this prediction.
Thinking about the regularisation approach described above, we could suppose \(M_k\) to be an identity matrix, representing a zero-order process model (so \(x_{k|k-1} = x_{k-1|k-1}\). The uncertainty matrix \(Q_k\) then plays the same role as \(C^{-1}\) above.
This part is just straightforward propagation of uncertainty.
The ‘clever’ part of the KF is the update step:
We suppose a linear observation operator \(H_k\) and an observation \(y_k\). Using the predicted state, we model an approximation to the observation \(\hat{y}\):
which gives a measurement residual \(r_k\):
The innovation (residual) uncertainty is:
where \(R_k\) is the measurement (and observation operator) uncertainty.
The (optimal) Kalman gain, \(K_k\) is:
which is essentially the ratio of the current state uncertainty and the residual uncertainty (mapped through the observation operator). Note that the Kalman gain is only a function of uncertainties.
The Kalman gain is applied to the residual to allow an update of the state:
The updated posterior uncertainty then is:
which expresses a reduction in uncertainty.
It is an interesting exercise to go through the derivation of the Kalman gain (see e.g. Wikipedia) though we will not do that here.
Clearly then, this is a sequential method: we update the state estimate whenever we have an observation, and trust to the model otherwise.
If the model is linear and the noise known and Gaussian, the KF can be a very effective DA method. If this is not the case, it can become rather unstable.
There are many variants of the Kalman filter that attempt to overcome some of its shortcomings.
Briefly, this includes:
Extended Kalman filter (EKF)
In which an attempt is made to deal with non-linearity by linearsing the operators.
Particle filter (PF)
Instead of linearising the operators, sample the distributions using Monte Carlo methods. (see Wikipedia for an excellent introduction)
Ensemble Kalman filter (EnKF)
Deal with non-linearities by running an ensemble (a set, if you like) of sample trajectories through the model.
13.2.4. Smoothers and filters
You will find the terms ‘smoothers’ and ‘filters’ in the DA literature. In essence, what this is is a distinction between whether the effective DA filter is applied only on time (or space) samples up to the current sample (a filter) or to samples both forward and backward in time (a smoother).
One way of thinking about this is to consider DA as a form of convolution filtering, with the filter being effectively a one-sided function, and the smoother being two-sided:
import numpy as np
import matplotlib.pyplot as plt
N = 1000
I = np.matrix(np.identity(N))
# generate the D matrix
D = (I - np.roll(I,1))
# squared for the constraint
D2 = D.T * D
D4 = D2.T * D2
sd = 1e-2
# inverse
F = (D2 + sd*sd*I).I
# plot the central line
y = np.array(F)[int(N/2)]
plt.subplot(2,1,1)
plt.plot(y/y.max(),label='Smoother')
plt.legend(loc='best',fancybox=True, shadow=True )
plt.subplot(2,1,2)
y[int(N/2):] = 0.
plt.plot(y/y.max(),label='Filter')
plt.legend(loc='best',fancybox=True, shadow=True )
plt.show()
(Source code, png, hires.png, pdf)
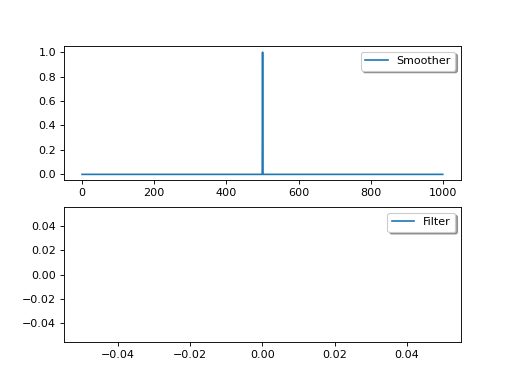{kind=link}
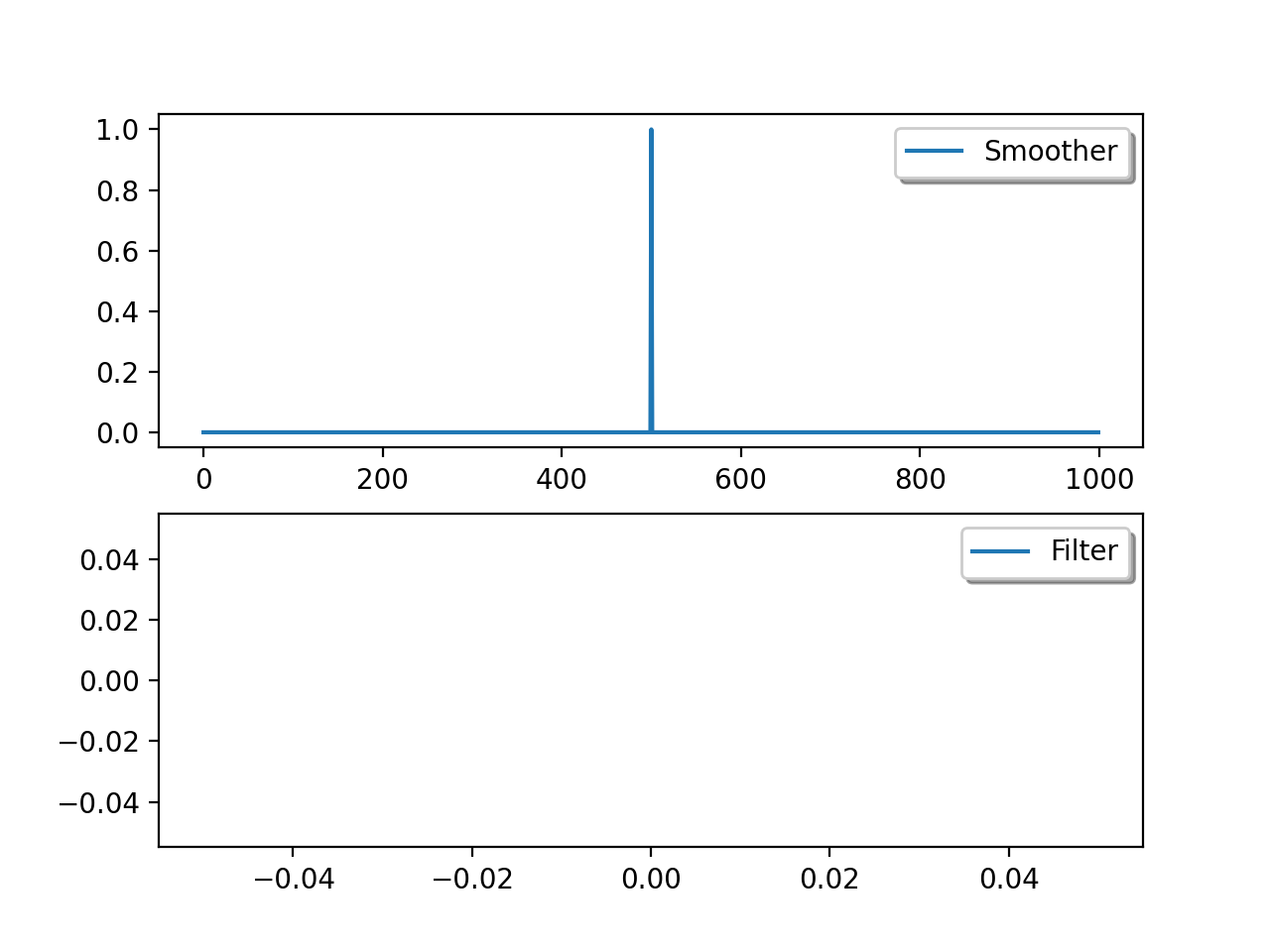{kind=link}
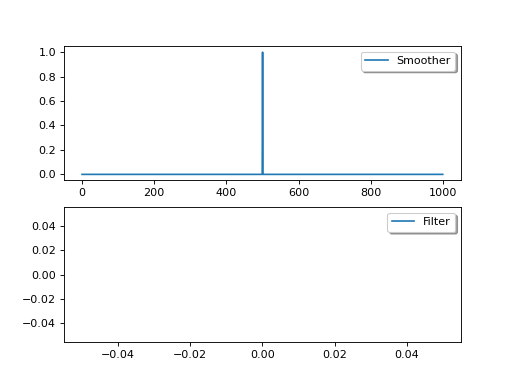
The variational methods we have shown above are generally smoothers as they apply the constraint to the whole time series, though of course when this is limited to an assimilation window, it is a smoother within the window, but a filter on the timestep of the window.
The estimate from a smoother will (in the absence of sudden changes) always provide a better estimate than the equivalent filter. But sometimes, implementing a smoother is more complex (in sequential cases, we need to make the model run backwards). Additionally, filters can be used for real time applications, whereas smoother cannot (we do not have observations into the future).
13.2.5. Markov Chain Monte Carlo
An extremely elegant, but often computationally expensive alternative to the DA methods given above is the Monte Carlo Markov Chain (MCMC) approach.
A common approach is the Metropolis-Hastings (MH) algorithm (see e.g. Chib and Greenberg, 1995 or the Wikipedia page).
There are clear step-by-step instructions for MH on Wikipedia.
At heart, an update of the state \(x\) is proposed, \(x'\), then a metric is calculated which weighs the likeihood of the new state relative to the old state. If the new state is an improvement, then it is selected as an update. If it is not (the metric \(a\) is less than 1), then a probability of \(a\) is assigned to taking this new step.
This is a Markov chain as it only concerns transitions from one state estimate to the next. A set of these Markov chains are sampled, each chain starting from arbitrary values.
Two major advantages of the approach are: (i) it can deal with arbitrary distributions (i.e. not just Gaussian); (ii) it will generally solve for the global optimum distribution (whereas many other approaches may get trapped in local minima).
13.3. Discussion
We have presented in this session some of the core ideas underlying data assimilation methods, starting from nothing beyong an appreciation of what a univariate mean and standard deviation are. An important part of any DA method is combining uncertainties, so we have been through that in some detail, both mathematically and graphically.
We have then reviewed some of the main methods used in DA, concentrating on variational methods and the Kalman filter, but mentioning other approaches. This should give you some awareness of the core methods out these to perform DA and some of the pros and cons of each approach.
13.4. Reading
Twomey, S., 2002. Introduction to the Mathematics of Inversion in Remote Sensing. Courier Dover Publications.
Wickle, C.K. and Berliner, L.M., (2012 in press) A Bayesian tutorial for data assimilation Physica D
Arulampalam, M.S., Maskell, S., Gordon, N. and Clapp, T. (2002) A Tutorial on Particle Filters for Online Nonlinear/Non-Gaussian Bayesian Tracking, IEEE TGRS 50,2, 174-188.
Greg Welch and Gary Bishop, 2007, An Introduction to the Kalman Filter
13.4.1. Suggested Reading
Hansen, P.C., Nagy, J.G., O’Leary, D.P. (2006) Deblurring Images: matrices, spectra and filtering, SIAM press.
Bouttier, F. and Courtier, P. (1999) Data assimilation concepts and methods
Chib, S. and Greenberg, E., 1995, Understanding the Metropolis-Hastings algorithm , The american statistician, 49, 4, 327-355.
Enting, I. G. (2002), Inverse Problems in Atmospheric Constituent Transport, 392 pp., Cambridge Univ. Press, New York.
Wikle C.K. and Berliner L.M. (2006) A Bayesian tutorial for data assimilation Physica D, doi:10.1016/j.physd.2006.09.017.
13.4.2. Advanced Reading
Kleeman, R. (2002) “Measuring Dynamical Prediction Utility Using Relative Entropy”, Journal of the atmospheric sciences, Vol. 59, 2057-2072.
Cover, T.M. and Cover, J.A, (1991) Elements of Information Theory, John Wiley & Sons, Print ISBN 0-471-06259-6 Online ISBN 0-471-20061-1